[Echo] 사람과 대화하는 인공지능 만들기(1)
며칠 전 인스타그램 릴스를 보다 인공지능 예술작품에 대한 흥미로운 동영상을 발견했다.
https://www.youtube.com/watch?v=uTCa5I9LwNc
위 영상은 노진아님의 개인전 '불완전모델' 로, AI를 활용한 '아기로봇'이 관객으로부터 말을 배우며 눈동자와 입의 움직임을 통해 인간과 AI의 상호관계를 느끼게 하는 예술작품이다.
로봇에게 '지금 뭐 하고 있니?'와 같은 질문을 하면 로봇 입이 위아래로 움직이며, '지금 대화 중이잖아, 당신이랑' 라고 답하는 등 다소 소름끼치는 사람과 대화하는 로봇의 모습을 확인 할 수 있다.

노진아님의 작품에 대해 더 알아보고 싶다면 인스타그램 계정을 참고하길 바란다.
https://www.instagram.com/reel/CyXRxlPJpUw/?igsh=MXkwdzRvOGxsOGlpOQ==
나는 이 영상속 '아기로봇'을 내가 사용할 수 있는 기술들로 흉내내보려고 한다.
먼저 아이디어 설계부터 해보자.
로봇의 이름을 정해야 하니 적당한 이름을 gpt를 활용하여 추출해봤다.
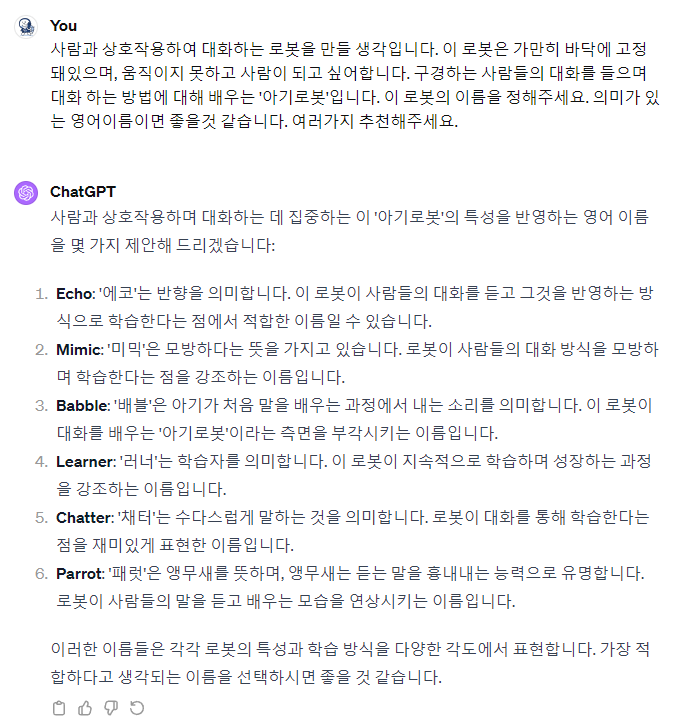
만들려고 하는 로봇의 특징을 입력하니, gpt가 여러 이름을 추천해주었고 나는 그 중에서 '에코'라는 이름이 마음에 들었다.
다음으로 할 것은 어떤 기술들을 사용해야 할 것인가이다.
사람과 상호작용하여 대화하는 인공지능을 만드는 방법은 여러가지가 있겠지만 '대화'가 가능하다는 것은 고수준의 자연어처리 기술을 적용해야 한다는 의미이고, 모델을 새롭게 만드려면 학습데이터도 많이 필요할 것이다.
나는 그정도 수준의 AI지식도, 비용도 없으므로 단순하게 생성 AI인 ChatGPT를 활용하여 사람의 질문에 대한 응답을 생성하는것으로 방향을 정했다.
ChatGPT API를 사용하면 GPT의 역할을 따로 설정 할 수 있으므로, GPT의 역할에 로봇의 설정과 성격, 말투, 등을 설정하면 우리가 만들고자 하는 로봇을 흉내낼수 있을것이라고 생각된다.
로봇은 우리의 말을 '듣고' 우리의 말에 대한 답변을 '말할 수' 있어야 한다.
컴퓨터는 우리의 말을 들을 수 있는 귀가 없기 때문에, 마이크를 통해서 우리가 한 말을 텍스트로 변환하여 이해하고, 다시 텍스트를 스피커를 통해서 말할 수 있다.
이러한 기술을 TTS(Text-To-Speech)와 STT(Speech-to-Text)라고 하며, TTS와 STT를 사용하기 위한 다양한 방법이 있지만, 간단하게 구글에서 지원하는 라이브러리를 사용할 예정이다.
TTS와 STT 라이브러리 사용방법에 대해 공부하고 싶다면 유튜브 '나도코딩'님의 인공지능 스피커 만들기 영상을 추천한다.
https://www.youtube.com/watch?v=WTul6LIjIBA
그럼 설계가 끝났으니 개발을 진행해보자.
1. 환경설정
언어는 Python을 사용할 예정이며, VSCode에서 개발할 예정이다.
여러 라이브러리를 설치해야하므로 가상환경을 설치하여 가상환경에서 개발을 진행해보자.
프로젝트 폴더에서 아래와 같이 입력하여 aienv라는 이름의 가상환경을 생성한다.
python -m venv aienv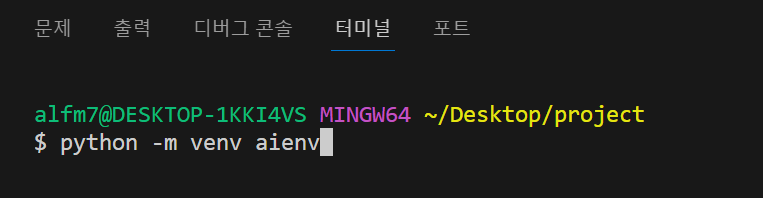
생성이 완료되었으면 명령어를 입력하여 가상환경을 실행한다.
.\aienv\Scripts\activate
아래와 같이 터미널 왼쪽에 가상환경의 이름이 표시되면 성공이다.

Text-to-Speech를 위한 라이브러리 먼저 설치해보자.
구글에서 제공해주는 라이브러리를 사용하기 위해 gTTS를 설치해야 한다.
추가로 소리파일을 실행하기 위한 라이브러리인 playsound도 설치해야하며, '나도코딩'님의 영상에서처럼, 업데이트 이후의 혹시 모를 문제상황을 방지하기 위해 1.2.2버전으로 설치한다.
pip install gTTS
pip install playsound==1.2.2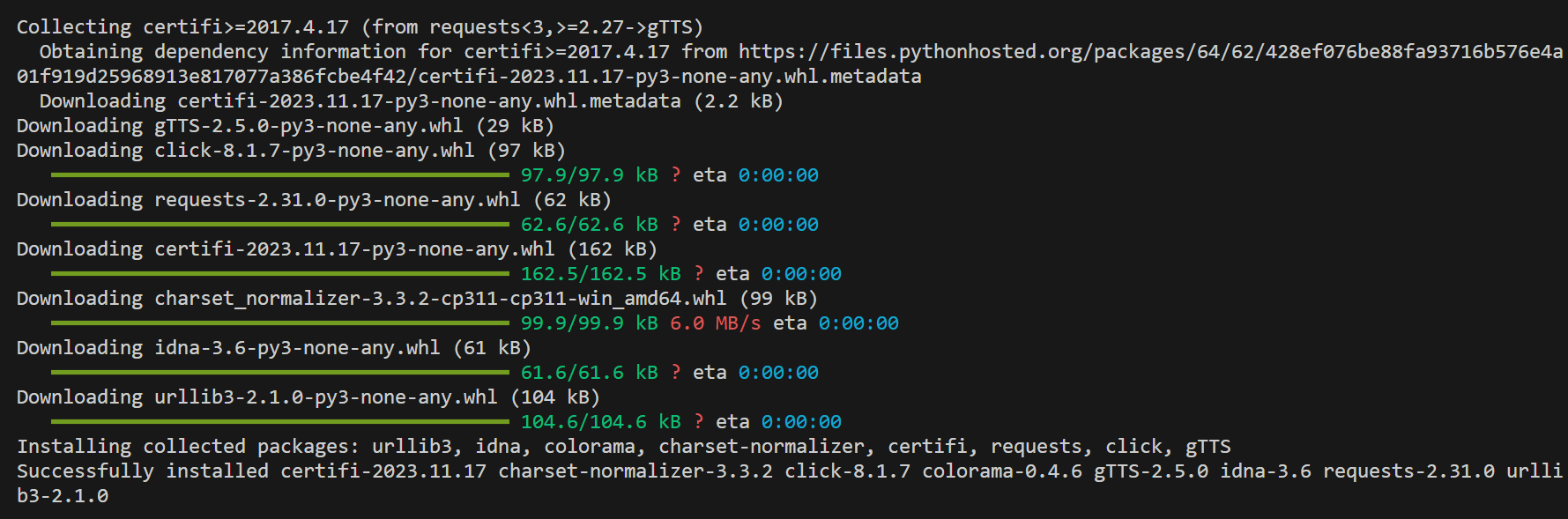
설치가 잘 됐는지 확인하기 위한 테스트 코드를 작성해보자.
from playsound import playsound
from gtts import gTTS
file_name = 'sample.mp3' # 저장할 파일 이름
# 한글 문장
text = "안녕하세요. 만나서 반갑습니다."
tts_ko = gTTS(text=text, lang='ko') # 문자 = 변수, 언어 = 한글 (한글로 저장)
tts_ko.save(file_name) # file_name을 이름으로 mp3파일 저장
playsound(file_name) # 저장한 mp3파일을 실행
gTTS 함수를 사용하면 매개변수로 전달받은 텍스트에 대해 설정한 언어로 말하는 음성 파일을 생성할 수 있다.
이 함수를 사용하여 GPT의 응답을 음성파일로 변환하여 출력할 것이다.
이제 Speech-To-Text 기능을 구현해보자.
설치해야 하는 라이브러리는 아래와 같다.
pip install SpeechRecognition
pip install PyAudio

설치가 끝났다면 테스트 코드를 작성하여 확인해보자.
from email.mime import audio
import speech_recognition as sr
r = sr.Recognizer() # Recognizer 객체를 r로 사용
with sr.Microphone() as source: # 마이크에서 들리는 음성(source)을 listen을 통해 들음
print("듣는중...")
audio = r.listen(source) # 마이크로부터 음성 듣기
# <작동 원리>
# 녹음된 데이터를 구글에 전송 => 구글 서버에서 작업 => 텍스트를 보게됨
# 서버로 음성 데이터를 보내므로 인터넷이 연결되어있어야함
try:
# 영어는 language = 'en-US'
text = r. recognize_google(audio, language='ko') # 한국어 음성으로 변환(STT)
print(text)
except sr.UnknownValueError: # 음성 인식이 실패한 경우
print("인식 실패")
except sr.RequestError as e: # 네트워크 등의 이유로 연결이 제대로 안됐을경우 API Key 오류, 네트워크 단절 등
print("요청 실패 : {0}".format(e))
# 말을 하면 마이크 모듈을 이용하여 source에 음성을 저장하고 audio에 저장
# 인터넷이 잘 연결 되어있다면, 혹은 다른 오류가 없다면 문자로 변환해줌
기본적인 작동원리는 코드에 주석으로 적어뒀듯이 SppechRecognition를 사용하여 마이크 모듈을 통해 입력된 사운드를 녹음하여 구글 서버로 전송하고, 구글 서버에서 작업을 마친뒤 결과물을 텍스트로서 반환해주는 것이다.
따라서 인터넷이 연결된 상황에만 라이브러리 사용이 가능하다.
이제 프로그램이 듣고 말할 수 있는 수단을 마련하였다.
앞서 작성한 TTS와 STT코드를 종합하여 프로그램의 뼈대를 만들어보자.
import time
import os
import speech_recognition as sr
from gtts import gTTS
from playsound import playsound
# 음성 인식(STT)
def stt(recognizer, audio):
try:
text = recognizer.recognize_google(audio, language='ko')
print("[사용자] " + text)
tts(text)
except sr.UnknownValueError:
print("인식 실패")
except sr.RequestError as e:
print("요청 실패 : {0}".format(e))
pass
def tts(input_text): # 어떤 대답을 할것인지 정의
answer_text = ''
if '안녕' in input_text:
answer_text = "안녕. 반가워"
elif '뭐 하고 있' in input_text: # '지금 뭐 하고 있어?', '뭐 하고 있니?', 등
answer_text = "지금 대화 중이잖아, 당신이랑"
elif '잘 있어' in input_text:
answer_text = "다음에 보자"
stop_listening(wait_for_stop=False) # 더이상 듣지 않음
elif '에코' in input_text:
answer_text = "왜 불러"
else:
answer_text = "무슨 말 하는건지 모르겠어"
speak(answer_text)
# 소리내어 읽기 (TTS)
def speak(text):
print('[에코] ' + text)
file_name = 'voice.mp3'
tts = gTTS(text=text, lang='ko') # 사용언어는 한글로
tts.save(file_name) # file_name으로 해당 mp3파일 저장
playsound(file_name) # 저장한 mp3파일을 읽어줌
if os.path.exists(file_name): # file_name 파일이 존재한다면
os.remove(file_name) # 실행 이후 mp3 파일 제거
r = sr.Recognizer()
m = sr.Microphone()
# background로 동작, m(마이크)를 통해 듣다가 stt함수 호출
stop_listening = r.listen_in_background(m, stt)
# 프로그램 종료 방지
while True:
time.sleep(0.1)
코드를 살펴보면 내가 작성한 tts함수에서 매개변수로 전달받은 텍스트를 바탕으로 조건식을 돌려 어떤 문자가 문장에 포함되어 있는지 파악하여 답변을 정의하는 것을 확인 할 수 있다.
현재까지 작성한 코드로는 일부 질문에 대한 응답만 가능할 뿐이므로, 사람과 상호작용하여 대화하는 AI라고 말할 수 없다.
따라서 조건식으로 작성한 코드를 수정하여 매번 다르게 답할 수 있도록 해야한다.
이 부분에 GPT API를 활용하여 AI의 두뇌를 대신하게 할 예정이며 글이 길어지는 관계로 다음 포스팅에서 이어서 작성하겠다.